Suppose I asked you to name a subset of the natural numbers that contained ‘most’ of them.
You might reply “‘Most’ could mean a lot of things”, or “Why are you trying to apply this sort of vague term to something so concrete as the natural numbers? Don’t you know what happens when you do things like that? Paradox, my friend.” So, maybe you think infinite sets are concrete, maybe you think you’re my friend, and maybe you think that every natural number being both ‘large’ and ‘small’ is a problem.
(If there’s no smallest large number, then they’re all large, even 0, but if there’s a smallest, say k, then k-1 is smaller and still large, a contradiction. So, either there’s a smallest large number – for example, 1,090,037 is large, but 1,090,036 is not – or else all numbers are large… or this is just a silly game to play.)
But suppose you ignore those things, and decide to play along with me, just for fun. Being forced to play my game you might start off, coyly, by proposing 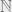 itself. A good choice actually – I would definitely agree that that set contains most of the natural numbers. How about the emptyset,
itself. A good choice actually – I would definitely agree that that set contains most of the natural numbers. How about the emptyset, 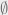 , the set containing no numbers, I ask. No, of course that’s not ‘most’, you’d say (I hope!). So we’ve got somewhere to start then: everything is most of something, and nothing is not most of anything.
, the set containing no numbers, I ask. No, of course that’s not ‘most’, you’d say (I hope!). So we’ve got somewhere to start then: everything is most of something, and nothing is not most of anything.
Perhaps your next proposal might be along the following lines: if we take the natural numbers and remove a finite number of them, say the set  , then we are left with a set that counts as ‘most’ of the naturals:
, then we are left with a set that counts as ‘most’ of the naturals:  . Happily, I’d agree – even if we take arbitrarily large finite amounts of elements out of the set, there are still infinitely many left, and an infinite set is certainly much larger than a finite set.
. Happily, I’d agree – even if we take arbitrarily large finite amounts of elements out of the set, there are still infinitely many left, and an infinite set is certainly much larger than a finite set.
Okay, what else? I’ll answer for you: if some set of natural numbers counts as ‘most’ of them, then I’m sure you’d agree that adding one more number (or many more) to the set leaves us with another set containing most natural numbers. Now here’s the tricky one – suppose I’ve got two sets of naturals, and we agree that teach contains ‘most’ of ; let’s call these sets A and B. As an example, we could let A be  and B be
and B be  . (Both sets miss only finitely many numbers, so by your earlier idea, they’re both ‘most’). Now form a new set, the intersection of A and B, by taking one of them, and removing any number not in both sets. We’d be left with
. (Both sets miss only finitely many numbers, so by your earlier idea, they’re both ‘most’). Now form a new set, the intersection of A and B, by taking one of them, and removing any number not in both sets. We’d be left with  , a set that still conforms to our earlier rule, and which should still count as ‘most’.
, a set that still conforms to our earlier rule, and which should still count as ‘most’.
Okay, then we’ve recovered a definition. Given a set X, a filter on X, call it  , is a notion of what subsets count as ‘most of X’; that is, it is a collection of ‘large’ subsets of X following the following rules:
, is a notion of what subsets count as ‘most of X’; that is, it is a collection of ‘large’ subsets of X following the following rules:
(i) 
(ii) if 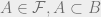 , then
, then 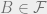
(iii) if 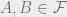 then
then 
First thing to notice is that even with a fixed X, there are many possible filters on it – just as two reasonable people might disagree on what counts as ‘most’ of something, there exist many different notions of ‘most’ on any given set. For example, on , we might ask whether the set of even numbers is large. What about the odds? Neither? Both? There are filters for each of these options except the last. Why not the last? Well, the thing to notice is that the evens are the complement of the odds – there is no number they have in common. Thus, their intersection is empty – so if a filter contains one, and the other – and so, they both contain ‘most’ naturals – then their intersection, by (iii), must also be in the filter. But (i) prohibits this. This is true of any set A – if it is in the filter, then its complement is not, and vice versa (and the other option is that neither is in).
Now, there are also going to be some filters which we will want to discount, even though they are not excluded in advance. These are filters that contain a finite subset (i.e. say that a finite set is ‘most’ of X). Intuitively, finite sets shouldn’t be large. If a finite set counts as ‘most’, then its complement, an infinite set missing only finitely many elements, would not count as large, as I just mentioned above. The rules above don’t exclude these filters, and we’ll have a convenient way to get rid of these when we shift our attention to ultrafilters, so I wont bother explicitly excluding them.
Before moving on to an ultrafilter, I think we need a reason to live – or at least, a reason to care about filters and ultrafilters. So, lets consider the following progression: 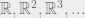 . What should come at the end of this sequence?
. What should come at the end of this sequence?
Let’s call it  .
.  is the set of n-tuples of reals, so is the set of infinite sequences of reals indexed by (so maybe we should have called it
is the set of n-tuples of reals, so is the set of infinite sequences of reals indexed by (so maybe we should have called it  ). The objects in this set are just sequences of reals which we came to know and love in calculus class. You did, right? Recall from calculus class that sequences either converge or don’t converge. If they converge, they converge to some real number, and if they don’t, there’s two reasons why that might happen. First, they might go to
). The objects in this set are just sequences of reals which we came to know and love in calculus class. You did, right? Recall from calculus class that sequences either converge or don’t converge. If they converge, they converge to some real number, and if they don’t, there’s two reasons why that might happen. First, they might go to 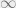 or
or  , and secondly, they might diverge because they just don’t any particular tendency as the sequence progresses – for example, the sequence
, and secondly, they might diverge because they just don’t any particular tendency as the sequence progresses – for example, the sequence 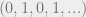 . So we can say that every sequence has a limit in
. So we can say that every sequence has a limit in  or else has no limit.
or else has no limit.
Why does this matter? Well, because, if we play our cards right, we can get ourselves a nice ordering on (or something like it) that turns it into a nice extension of the real numbers. And one which contains infinitesimal and infinite elements in a perfectly consistent, understandable and useful fashion. I’ll leave explaining why such an extension would be a nice thing to have for a later post. But for now, it basically gives us a sandbox other than the real numbers in which we can do all the usual things in calculus (differentiate, integrate, make theorems etc.) but without epsilson-delta arguments, and with what some would argue is a higher degree of intuitiveness. (Sridhar may want to discuss an alternate construction of infinitesimal calculus, but this will remain, deaf to what he has to say, my favourite.)
Now, why aren’t any of the existing orderings on good enough for us? Here’s one reason: the following sequences all have 1 as their limit

however, they are all different sequences so they are all different elements of . And so, they need to be put in some order. Which should be ‘greater’ than which? Well, if we put them in lexicographic ordering, we get  and if we reverse the lexiographic ordering we get the reverse, and neither is particularly appealing. Similarly,
and if we reverse the lexiographic ordering we get the reverse, and neither is particularly appealing. Similarly, 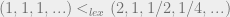 , even though the first has limit 1 and the second has limit 0.
, even though the first has limit 1 and the second has limit 0.
Ultrafilters let us deal with this problem gracefully – we will capture the limit rule that changing a finite number of entries in a sequence doesn’t change the limit by saying that the sequences 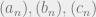 are all equal! How does this work? What we do, in effect, is say that two sequences are in some relation (<, >, or =) to each other just if most of their indices have that property. That is, one sequence
are all equal! How does this work? What we do, in effect, is say that two sequences are in some relation (<, >, or =) to each other just if most of their indices have that property. That is, one sequence  will be less than another,
will be less than another, 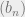 , just if on a large set of indices i, we have
, just if on a large set of indices i, we have  .
.
Okay, so why the ultra? Well, suppose we have a filter on the natural numbers that says that neither the even numbers nor the odds are large. And consider the sequences  and
and  – in order to figure out which of these sequences is greater than the other (or if they are equal), we check if they have that property on a large set. However, since neither the evens nor the odds are large, there is no large set where the differ (so neither is greater than the other), and since they are equal nowhere, there is no large set where they are equal. Thus, our filter’s indecision about the evens and odds has become an indecision about which sequence is greater than which.
– in order to figure out which of these sequences is greater than the other (or if they are equal), we check if they have that property on a large set. However, since neither the evens nor the odds are large, there is no large set where the differ (so neither is greater than the other), and since they are equal nowhere, there is no large set where they are equal. Thus, our filter’s indecision about the evens and odds has become an indecision about which sequence is greater than which.
To solve this, we add the following restriction to the definition of a filter to get an ultrafilter:
(iv) for every subset A of X, either 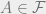 or
or 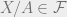 .
.
That is, every set is either large, or its complement is large. Now, you may smell arbitrariness coming your way. And the above example is also an example of this: to get an ultrafilter, we need to make some decision, arbitrary though it may be, about whether the evens or odds are large. As well, there will be many other subsets and their complements about which a filter is not required to make a decision. Thus, in order to make ultrafilters, there is going to be an infinite amount of arbitrary decision making going on. I’ll stop here, and continue in the next post with ultrafilters, and more of the story of .

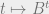



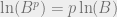
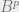








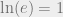

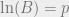



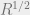

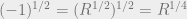
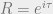
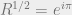

 . “What a mystical coincidence! What on earth do
. “What a mystical coincidence! What on earth do  , and
, and 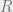 to mean the action of one full revolution (360 degree rotation).
to mean the action of one full revolution (360 degree rotation).  . And
. And  , a quarter revolution (90 degree rotation).
, a quarter revolution (90 degree rotation).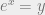 is by definition equivalent to
is by definition equivalent to  . The natural logarithm, in turn, is defined so that
. The natural logarithm, in turn, is defined so that  per unit of time is the constant ratio between an exponentially growing quantity’s velocity and the quantity itself, where the quantity multiplies by
per unit of time is the constant ratio between an exponentially growing quantity’s velocity and the quantity itself, where the quantity multiplies by  over every unit of time. (In calculus jargon,
over every unit of time. (In calculus jargon, 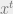 with respect to
with respect to  )
) for rotation by one radian. Radians, of course, are the normalized unit of rotation in the sense that swinging through one radian is the same as swinging through an arclength equal to the radius; in other words,
for rotation by one radian. Radians, of course, are the normalized unit of rotation in the sense that swinging through one radian is the same as swinging through an arclength equal to the radius; in other words,  is
is 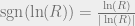 , the purely directional component of
, the purely directional component of  is the number of radians in a full revolution; that is,
is the number of radians in a full revolution; that is,  , which is to say,
, which is to say, 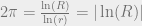 .
. . In other words, that
. In other words, that  (the form the claim would be presented in if one cared more about
(the form the claim would be presented in if one cared more about 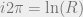 . By the definition of
. By the definition of  . Finally, by the definitions of
. Finally, by the definitions of 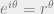 in general**). That’s all there is to it.
in general**). That’s all there is to it. . This is just a change in the presentation of the same simple geometric fact; sometimes it’s helpful to split things into co-ordinates, and sometimes it’s distracting.
. This is just a change in the presentation of the same simple geometric fact; sometimes it’s helpful to split things into co-ordinates, and sometimes it’s distracting.